
La recente ricerca condotta dal MIT, in collaborazione con il MIT-IBM Watson AI Lab, esplora una metodologia innovativa per migliorare la navigazione dei robot utilizzando i grandi modelli linguistici (LLM). Questo approccio mira a superare le limitazioni delle tecniche tradizionali basate su rappresentazioni visive, che richiedono grandi quantità di dati visivi e un notevole sforzo umano per la costruzione dei modelli.
Soluzione a un problema di visione con il linguaggio
Gli attuali approcci alla navigazione dei robot utilizzano molteplici modelli di machine learning, ognuno specializzato in una parte del compito. Questi metodi necessitano di grandi quantità di dati visivi, spesso difficili da ottenere. I ricercatori del MIT hanno ideato una soluzione che converte le rappresentazioni visive in descrizioni testuali, che vengono poi elaborate da un grande modello linguistico per determinare le azioni che il robot deve compiere.
Il metodo proposto sfrutta modelli di captioning per ottenere descrizioni testuali delle osservazioni visive del robot. Queste descrizioni vengono combinate con le istruzioni linguistiche dell’utente e inserite in un modello linguistico, che decide il passo successivo per la navigazione. Questo approccio permette di generare rapidamente una grande quantità di dati di addestramento sintetici, utilizzando meno risorse computazionali rispetto alle tecniche basate su immagini complesse.
Vantaggi dell’utilizzo del linguaggio
Nonostante il metodo non superi le tecniche basate sulla visione in termini di prestazioni, presenta diversi vantaggi. La generazione di dati testuali richiede meno risorse computazionali, permettendo di creare rapidamente grandi quantità di dati di addestramento sintetici. Inoltre, il linguaggio può colmare il divario tra gli ambienti simulati e il mondo reale, dove le immagini generate al computer possono differire significativamente dalle scene reali.
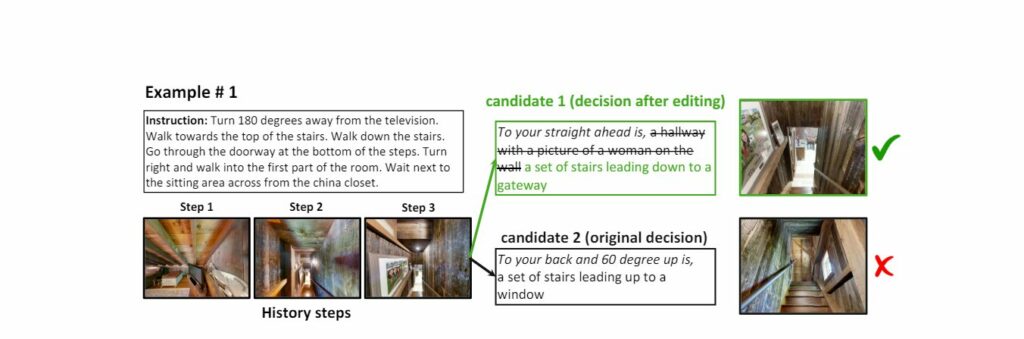
Le rappresentazioni testuali sono più comprensibili per gli esseri umani, facilitando l’identificazione dei punti di fallimento del robot. Questo metodo può essere applicato a una varietà di compiti e ambienti, poiché utilizza un unico tipo di input: il linguaggio. Tuttavia, un limite di questa metodologia è la perdita di informazioni che sarebbero catturate da modelli basati sulla visione, come le informazioni sulla profondità.
Prospettive future
I ricercatori intendono esplorare ulteriormente la combinazione delle rappresentazioni basate sul linguaggio con i metodi basati sulla visione, che ha mostrato miglioramenti nelle capacità di navigazione dei robot. Un’area di interesse futuro è lo sviluppo di un modello di captioning orientato alla navigazione per migliorare ulteriormente le prestazioni. Inoltre, si vuole indagare la capacità dei grandi modelli linguistici di mostrare consapevolezza spaziale e come ciò possa supportare la navigazione basata sul linguaggio.
Questa ricerca, supportata dal MIT-IBM Watson AI Lab, rappresenta un passo significativo verso l’integrazione di tecniche linguistiche e visive per migliorare la navigazione dei robot, rendendola più efficiente e comprensibile grazie agli LLM.